Amazon S3 is one of the several cloud storage solutions provided by the Internet giant Amazon Inc. It offers a highly secure and versatile storage mode to store documents, images, music, videos, and all other file types. Amazon S3 allows users to create “buckets” in which they can create custom folders and save their data. Think of a bucket as a hard disk partition.
Amazon S3 is a big player in the cloud storage market because of the benefits it provides. The flexibility and the value combine into a more productive, and seamless experience for the end-user, whether they are just an average user or an enterprise.
Cloud users often land themselves into a mess by not properly organizing their data. Organizing the data includes dividing the files into relevant folders and naming the files properly. A randomly named document will take ages to discover.
Data that is poorly organized means searching for a particular file will turn into a frustrating experience. This also means there are maximum chances of duplicate data. This can happen either directly when the user can’t locate a particular file, they will choose to take the easier route of downloading it again (and syncing it to Amazon S3), rather than spending a long time to locate it on the cloud.
Duplicate data can also be created in an indirect manner when the user is totally unaware of duplicates occupying their cloud storage. Since they are not organizing their data and basically dump their files randomly, who knows how deep the actual mess is.
How would you feel when you discover you have been paying that subscription fee just to support loads of duplicate files sit on the cloud? How bad would you feel when you realize you couldn’t save a very important folder to your Amazon S3 drive because the drive had run out of space?
Let’s talk about the solution in some detail.
In comes Cloud Duplicate Finder, a secure, state-of-the-art web-service that employs the most technologically advanced protocols to ensure your cloud data undergoes a safe and secure scan to detect duplicate files in Amazon S3 Buckets and other Cloud Drives. Cloud Duplicate Finder performs this scan by using the official APIs provided by the respective cloud service provider (Amazon Web Services in this case).
It employs 256-bit encryption throughout the process to ensure an additional layer of security. All you have to do is to register for an account at CDF and subscribe to one of the membership plans on offer. From there onwards, the process is as follows:
- Navigate to the App page of Cloud Duplicate Finder. This is the scan area where all the magic will happen.
- Now select the Amazon S3 tab.
- Click the Add New Drive button on the left.
- Now enter the Bucket Name (you can scan 1 bucket at a time), Access Key ID and Secret Key and click Add Bucket.
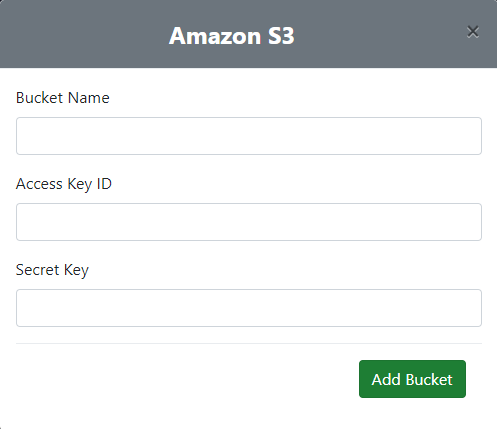
Adding up the Amazon S3 bucket
- Now you will be seeing all of the folders inside this bucket in the left-hand pane of the CDF interface. Select all the folders you want to scan.
- The next step allows you to choose specific file types for the scan. We suggest going with the All Files option. Limiting the scan to a single/ few file types does come in handy if you are sure what file type the duplicates are.

- Now we’re all set for the scan, so click the Scan button and be prepared to get results that will surprise you very soon.
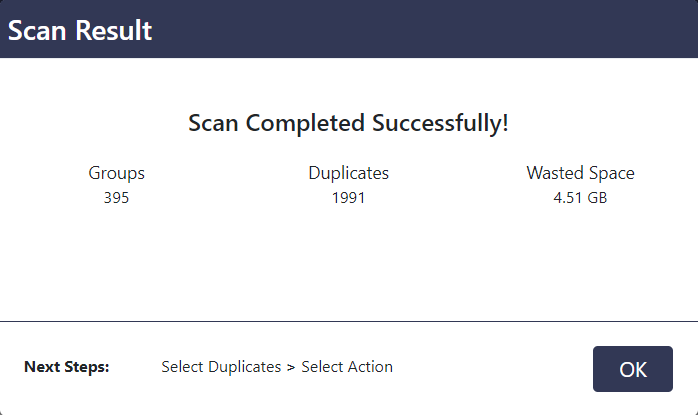
The scan results popup
- Cloud Duplicate Finder will now list out all the duplicates divided into groups. CDF only shows 100 duplicates per page, so you will have to click the Next/ Previous buttons in the footer to move across pages.

- Now you can choose whether to select the duplicates for further action manually, or using the Select Duplicates button for a speedy and proper operation.
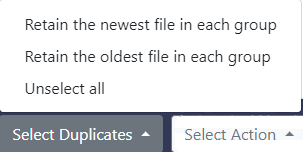
Selecting the duplicates
- Now you have to simply click the Select Action button and then click on Permanent Delete.
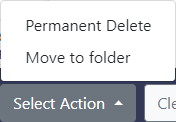
Note: The Move to folder option is not available for Amazon S3 because of restrictions imposed by their API.
That’s it. Freeing up a whole lot of duplicate data from your Amazon S3 drive is very easy and a must-do kind of thing. Sign up for a Cloud Duplicate Finder account today and let the duplicate cleanup begin.

Warning: Undefined array key "author_box_bio_source" in /home1/clonefil/public_html/blog/wp-content/plugins/molongui-authorship/views/author-box/parts/html-bio.php on line 2
Raza Ali Kazmi works as an editor and technology content writer at Sorcim Technologies (Pvt) Ltd. He loves to pen down articles on a wide array of technology related topics and has also been diligently testing software solutions on Windows & Mac platforms. If you have any question about the content, you can message me or the company's support team.